Intel N100 홈서버 실전 구성: VM과 Docker 역할 분리 설계하기
도입
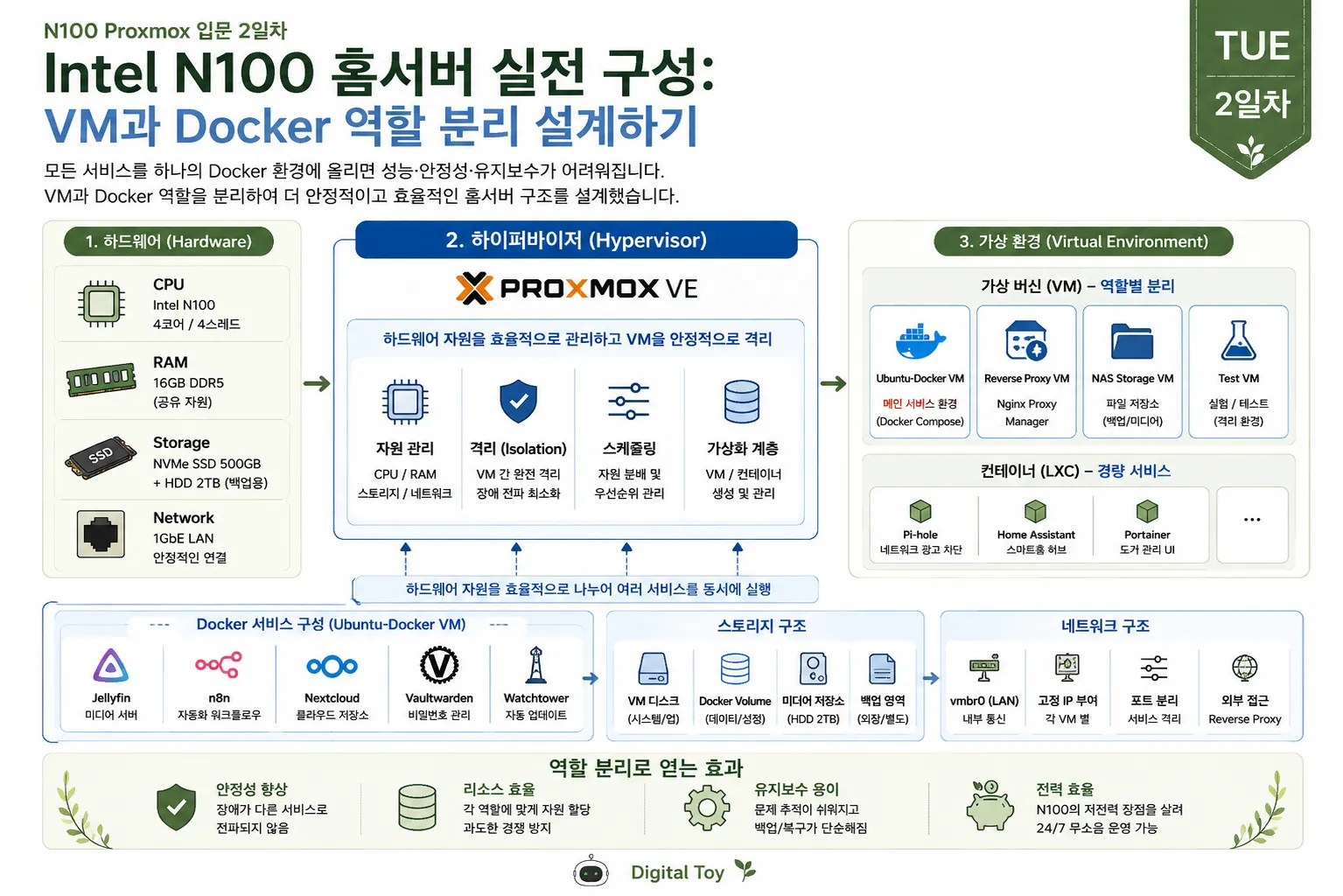
월요일에는 Proxmox VE 하이퍼바이저 구조와 VM, 그리고 LXC 컨테이너의 차이에 대해 정리해봤습니다. 오늘은 이 개념들을 실제로 Intel N100 홈서버에 어떻게 적용할 수 있을지 이야기해보려고 합니다.
처음에는 Ubuntu VM 하나에 Docker Compose로 모든 서비스를 올리는 게 가장 단순할 거라고 생각했습니다. Jellyfin, n8n, 리버스 프록시, Portainer 같은 것들을 한 곳에서 관리하면 확실히 편할 것 같았죠. 그런데 며칠 운영해 보니, 컨테이너만 분리되어 있다고 해서 운영 리소스까지 완전히 분리되는 건 아니라는 사실을 깨달았어요. 두 가지는 생각보다 전혀 다른 문제더라고요.
출처: 디지털 장난감
※ 다이어그램은 운영 환경 설계를 바탕으로 AI 도구를 활용해 제작했으며, 최종 구성과 내용은 운영자가 직접 검수했습니다.
본문
처음에는 하나의 Docker VM에 모두 올렸다
처음에는 아주 단순하게 시작했습니다. Proxmox VE 위에 Ubuntu Server 가상머신을 하나 만들고, 그 안에서 Docker Compose를 사용해 여러 가지 서비스를 돌렸죠. 이렇게 하면 구축 속도가 빠르고, 관리해야 할 부분도 적어서 편리했습니다.
Proxmox VE
└─ Ubuntu-Docker VM
├─ Reverse Proxy
├─ n8n
├─ Jellyfin
├─ Portainer
└─ 테스트용 컨테이너작은 규모로 홈서버를 운영할 때는 이렇게 한 파일에 모든 서비스를 모아 두는 방식이 참 편리합니다. 볼륨 경로만 잘 정리해두면 금방 서버를 돌릴 수 있죠. 그런데 서비스가 하나둘 늘어나기 시작하면, 이야기가 조금 달라집니다. 그때부터는 관리가 점점 복잡해집니다.
컨테이너는 겉으로 보기엔 각각 따로 돌아가는 것 같아도, 결국 하나의 Ubuntu VM 안에서 같은 CPU, RAM, 디스크 I/O를 나눠 쓰게 됩니다. 그래서 Jellyfin이 라이브러리 스캔을 시작한다거나 Docker 이미지 업데이트가 동시에 이루어질 때, n8n이나 리버스 프록시의 응답 속도까지 덩달아 느려지는 일이 생길 수 있습니다.
컨테이너 분리와 운영 분리는 다르다
Docker 컨테이너는 애플리케이션을 분리하는 데 정말 유용합니다. 하지만 모든 컨테이너를 하나의 가상머신에 몰아 넣으면, 리소스가 한 곳에서 막혀 병목 현상이 생길 수밖에 없습니다. 특히 N100처럼 저전력 미니PC에서는 짧은 순간의 부하보다 여러 작업이 한꺼번에 겹칠 때 더 큰 문제가 발생합니다.
- Jellyfin에서 라이브러리를 스캔할 때 CPU 사용률이 잠깐 크게 올랐습니다.
- Docker 이미지를 업데이트하는 작업과 백업이 동시에 진행되면, 디스크 I/O가 갑자기 치솟는 경향이 보였습니다.
- Reverse Proxy와 실험용 컨테이너를 같은 VM에 두니까, 장애가 발생했을 때 원인을 찾는 일이 더 복잡해 졌습니다.
- 로그 파일과 볼륨 데이터가 하나의 디스크 공간에 함께 저장되다 보니, 어느 쪽에서 용량이 늘어나는지 파악하기가 쉽지 않았습니다.
이번 구성에서 가장 중요한 점은 ‘Docker를 얼마나 많이 올릴 수 있느냐’가 아니라, ‘어떤 서비스를 한 영역에 묶고, 어떤 서비스는 따로 분리할지’에 대한 고민이었습니다.
역할별 VM 구조를 다시 잡아봤다
구조를 다시 잡으면서 가장 먼저 생각한 기준은 운영의 안정성과 장애가 발생했을 때 그 원인을 쉽게 파악할 수 있는지였습니다. 모든 서비스를 완전히 분리하면 관리가 복잡해지지만, 반대로 성격이 다른 여러 서비스를 한데 모아두면 문제가 생겼을 때 어디서 문제가 발생했는지 찾기 어려워집니다.
| 구성 영역 | 역할 | 예상 RAM | 운영 판단 |
|---|---|---|---|
| Ubuntu-Docker VM | n8n, Portainer, 일반 Docker 서비스 | 4GB | 메인 서비스 운영 영역 |
| Reverse Proxy VM | 외부 접속, 도메인 연결, SSL 관리 | 1~2GB | 외부 연결 계층 분리 |
| Media VM | Jellyfin, 미디어 스캔 | 4GB 이상 | 부하 변동이 커서 분리 고려 |
| Test VM | 새 서비스 실험, 설정 테스트 | 2GB | 운영 환경 오염 방지 |
| Backup / Storage 영역 | 백업 파일, 로그 보관, 외장 저장소 | 별도 관리 | VM 디스크와 백업 경로 분리 |
이 표가 반드시 따라야 할 정답은 아닙니다. 오히려 N100 환경에서는 VM을 너무 많이 만들면 오히려 메모리나 디스크 관리가 복잡해질 수 있습니다. 핵심은 부하가 많이 걸리는 서비스, 외부 접속 계층, 그리고 실험 환경을 꼭 필요한 만큼만 분리해두는 데 있습니다.
Docker Compose는 운영 단위로 나눴다
Docker Compose 파일을 하나로만 관리하면 처음에는 편리하게 느껴질 수 있지만, 시간이 지나면서 각 서비스가 어떤 볼륨을 사용하는지나 어떤 포트를 열고 있는지 점점 헷갈리기 시작합니다. 그래서 저는 서비스의 성격에 따라 Compose 파일을 나누는 것이 더 관리하기 쉬웠습니다. 이렇게 분리해두면 나중에 수정이나 점검할 때도 훨씬 수월해집니다.
/opt/docker/
├─ proxy/
│ └─ docker-compose.yml
├─ automation/
│ └─ docker-compose.yml
├─ media/
│ └─ docker-compose.yml
└─ test/
└─ docker-compose.yml운영용 서비스와 테스트용 서비스를 따로 분리해두면, 새로운 컨테이너를 시험하다가 문제가 생기더라도 기존 서비스에는 큰 영향을 주지 않습니다. 이렇게 Proxmox 위에 Docker를 올려서 사용하는 방식이 바로 이런 점에서 장점을 갖고 있습니다.
services:
n8n:
image: n8nio/n8n:latest
restart: unless-stopped
volumes:
- ./data:/home/node/.n8n
ports:
- "5678:5678"여기서 restart: unless-stopped를 선택한 이유는 간단합니다. 서버를 재부팅하면 서비스가 자동으로 다시 실행되지만, 운영자가 일부러 멈춘 서비스까지 무조건 재시작되게 하고 싶지는 않았기 때문이죠. 홈서버 환경에서는 서비스가 자동으로 복구되는 것도 중요하지만, 운영자가 직접 통제한 상황을 그대로 유지하는 것도 무시할 수 없는 부분입니다.
스토리지 병목은 생각보다 빨리 드러났다
VM 디스크, Docker 볼륨, 로그, 백업 파일을 모두 같은 NVMe 저장소에 두면 처음에는 별다른 문제가 없어 보일 수 있습니다. 하지만 백업이나 미디어 스캔, 이미지 업데이트 작업이 동시에 진행되기 시작하면, 점점 디스크 응답 속도가 눈에 띄게 느려질 수 있습니다. 특히 여러 입출력 작업이 한꺼번에 몰릴 때 이런 현상이 더 두드러집니다.
이럴 때 단순히 "N100이라서 느리다"고 단정하기보다는, 같은 시간대에 어떤 작업들이 같은 저장소를 함께 사용하고 있는지 먼저 확인해보는 것이 더 정확합니다.
# 디스크 사용량 확인
df -h
# Docker 이미지와 볼륨 사용량 확인
docker system df
# 디스크 I/O 확인
iostat -xz 1iostat은 기본적으로 설치되어 있지 않은 경우가 있습니다. Debian/Ubuntu 같은 계열에서는 sysstat 패키지에 이미 포함되어 있어서, 필요하다면 따로 설치해서 확인할 수 있습니다.
sudo apt install sysstat이번 실험을 통해 얻은 결론은 백업, 로그, VM 디스크를 최대한 따로 관리하는 게 좋다는 점이었습니다. 물리적으로 저장소가 하나뿐이어도 경로나 작업 시간을 분리해 두면 나중에 문제가 생겼을 때 원인을 찾기가 훨씬 수월해집니다.
리소스 확인은 감이 아니라 숫자로 봐야 한다
홈서버를 처음 운영할 때는 “느린 것 같다”거나 “그럭저럭 괜찮은 것 같다”처럼 느낌에 따라 판단하기 쉽죠. 그런데 막상 들여다보면, 병목 현상이 CPU보다는 오히려 메모리나 디스크 I/O, 네트워크 응답 쪽에서 더 자주 발생하는 경우가 많았습니다.
# 컨테이너별 실시간 사용량
docker stats
# VM 내부 프로세스 확인
htop
# 디스크 사용량
df -h
# Docker 누적 사용량
docker system df특히 Docker 기반 홈서버에서는 docker stats로 컨테이너별 사용량을 보고, Proxmox Web UI에서는 VM 전체 사용량을 함께 보는 방식이 좋았습니다. 컨테이너 단위와 VM 단위를 함께 살펴봐야 어디에서 병목이 발생하는지 정확히 알 수 있습니다.
운영 로그
아래 표는 VM과 Docker의 역할을 분리하는 설계를 진행하면서 확인했던 운영 기준을 정리한 것입니다. 표에 나와 있는 수치는 장비의 사양이나 서비스 구성에 따라 달라질 수 있으니, 기준값 자체보다는 수치가 어떻게 변하는지, 변화의 흐름을 살펴보는 것이 더 중요합니다.
| 점검 항목 | 확인 방법 | 해석 기준 |
|---|---|---|
| VM 전체 부하 | Proxmox Web UI | VM별 CPU/RAM 사용률 비교 |
| 컨테이너 부하 | docker stats |
특정 컨테이너의 CPU/RAM 급증 여부 |
| 디스크 사용량 | df -h |
로그·백업·볼륨 증가 추세 확인 |
| Docker 누적 용량 | docker system df |
이미지·볼륨 정리 필요 여부 |
| 스토리지 I/O | iostat -xz 1 |
백업·스캔 시간대 I/O 지연 확인 |
| 네트워크 구조 | ip a, Proxmox vmbr0 |
VM과 Reverse Proxy 연결 흐름 확인 |
에디터의 해석 노트 (Editor's Lab Note)
- 이번 글의 핵심은 “서비스를 많이 올리는 것”보다 “서비스 성격에 맞게 역할을 나누는 것”이었습니다.
- Docker 컨테이너는 분리되어 보이지만, 같은 VM 안에서는 CPU·RAM·I/O 자원을 공유합니다.
- N100 환경에서는 무리한 확장보다 부하가 큰 서비스, 외부 접속 계층, 테스트 환경을 구분하는 쪽이 더 현실적이었습니다.
- 구조를 나눌 때는 멋진 설계보다 장애가 났을 때 어디부터 확인할 수 있는지가 더 중요했습니다.
참고 링크 (References)
트러블슈팅
문제: 컨테이너는 모두 실행 중인데 홈서버 응답이 느려짐
Docker Compose 기준으로 보면 모든 컨테이너가 Up 상태인데도, Web UI 접속이 느려지거나 Reverse Proxy 응답이 지연되는 경우가 있습니다. 이때는 컨테이너 실행 여부만 볼 것이 아니라 VM 전체 리소스와 디스크 I/O를 함께 확인해야 합니다.
확인: 컨테이너 상태, VM 부하, 디스크 사용량을 함께 점검
# 컨테이너 상태
docker compose ps
# 컨테이너별 리소스 사용량
docker stats
# 디스크 사용량
df -h
# Docker 이미지·볼륨 사용량
docker system df
# 디스크 I/O 확인
iostat -xz 1원인: 여러 Docker 서비스가 같은 VM 자원과 같은 NVMe 저장소를 동시에 사용함
해결: 부하가 큰 서비스와 외부 연결 계층, 실험용 서비스를 분리하고 백업·스캔 작업 시간을 나눔
컨테이너가 살아 있다고 해서 운영이 항상 안정적인 건 아닙니다. N100 홈서버에서는 VM, Docker, 저장소 상태까지 함께 점검하면서 어디서 병목이 생기는지 살펴보는 습관이 필요했습니다.
마무리
Intel N100 홈서버에서 Proxmox VE와 Docker를 함께 사용할 때 중요한 것은 “얼마나 많은 서비스를 올릴 수 있는가”보다 “어떤 기준으로 나눠서 운영할 것인가”였습니다.
하나의 Ubuntu VM에 모든 Docker 서비스를 올리는 구조는 시작하기 쉽지만, 시간이 지나면 로그, 백업, 미디어 스캔, 업데이트 작업이 서로 영향을 주기 시작합니다. 그래서 운영용 서비스, 외부 접속 계층, 실험 환경, 백업 영역을 어느 정도 구분하는 것이 더 안정적이었습니다.
수요일에는 이 구조 위에서 실제로 마주칠 수 있는 CPU 가상화 플래그 문제와 Proxmox 환경의 VT-x 인식 오류 흐름을 이어서 정리해보겠습니다.
'코어-테크 : 트러블 슈팅 노트' 카테고리의 다른 글
| Intel N100 홈서버 운영 최적화 : Proxmox + Docker 자동 재시작과 로그 관리 정리 (0) | 2026.05.21 |
|---|---|
| Intel N100 홈서버 트러블슈팅: VT-x와 가상화 옵션 문제 해결하기 (0) | 2026.05.20 |
| N100 Proxmox 입문: 가상화 구조를 이해하면 홈서버가 쉬워진다 (1) | 2026.05.18 |
| Intel N100 홈서버 1주차 회고 : 운영 기록과 다음 주 운영 방향 정리 (0) | 2026.05.17 |
| Intel N100 홈서버 운영 기록 정리 : 전력·온도·서비스 상태를 데이터로 남기기 (0) | 2026.05.16 |



